Microservices Architectures

As part of API development, there are a lot of patterns or
architecture that will be available. We can't stick with one pattern as part of
large distributed application development. An application can be developed with
multiple patterns based on the use cases as well as application performance
also.
I have created multiple services with multiple architectures
or patterns based on the multiple-use case in order to achieve the best
results.
I have started creating the microservices for my
application. Because my application involves multiple entities. Each entity
playing a major role in the corresponding services. Based on my need I can
scale, extend, and migrate the corresponding service. I have created multiple
services. I need to provide my services to the consumers. Here my consumers are
web applications and native applications.
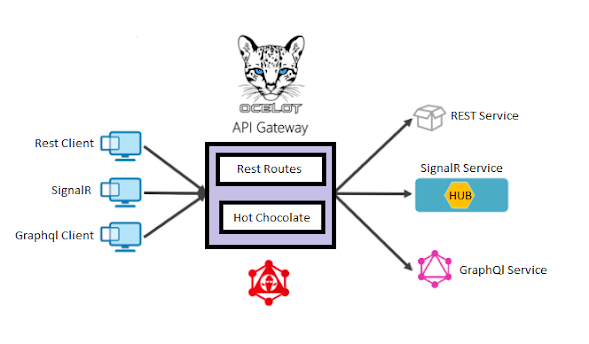
Apigateway:
All the consumers need to consume the services via
endpoints or URL. As part of services development, we can add or update a
number of endpoints based on the business. Because of that consumers doesn't
require to change API endpoints as well as the resource path. The client can
stick with endpoints. The client doesn't require to know each and every service
endpoint. In this case, they need a simple URL for the request and response.
Using Apigateway we can provide the resource URL. Background we can point to
any services based on our need. I need to forward the client request to the
corresponding service. So I need some passthrough layer to map the consumer
request to services. so I have chosen the API gateway. It will maintain all the
services we want to expose to the consumers and resources path also. It will do
the authentication. All my requests will be authenticated in my API gateway
itself. Authorization we can do it in API gateway or corresponding service based
on our need. It's a one way in and out. Consumers can consume all my services
using the gateway alone.
DB Per
Service:
Once the gateway redirects the consumer requests to the
corresponding services. Individual service needs to get the data from the DB.
How my DB will be. It will belong to current services or all other services.
All my data will belong to a particular set of tables. Other services will not
consume those tables. It will be used only by these services. But in real-time
it will not be. Might be one or more tables will be used to maintain the
relationship between the entity. Then corresponding services also will use
those tables. In this case, we need to decide either we need to keep the table
inside or move to the common one. It will be purely based on how frequently we
are making the request and the rest of the services to consume this table.
Sometimes I have moved the cross table to other entities or commonly based on
the performance, load, and business. Sometimes I have a chance to have all the
tables relevant to the entity. In this case, this DB and tables will belong to
this service alone. I have created a separate DB or schema for those tables
alone. Db and service fully interconnected with each other. The corresponding
tables fully disconnected from the rest of the entities. So scalability will be
very easy. I can move my service and my DB to anywhere based on my need.
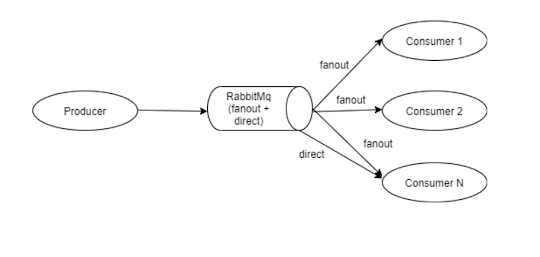
Event
Sourcing:
All my services are running fine. For some of my services,
I am doing some operation. based on that
I need to do some other operations on other services. I can call those
operations from the current service using API calls but its lead increase the
API response time. Because I need to know whether the API call is a success or
not. Current API doesn't require to wait until the other operations need to
complete. This is where we need to publish the events. List of entities that
need to perform the operations they will listen to those events and complete
the subsequent operations. It will reduce the service dependencies but will
increase the application complexity. We can publish the methods using different
service providers like RabbiMq, Kaffka. It's called Pub/Sub.
SAGA:
All my transaction has been completed successfully on
different services. Suppose one of my operations is getting failed. Even after
the number of retries still, those operations are getting failed. Without this
operation, the entire transaction will not be completed. It will question the
application's reliability. In this case, we need to revert what is the
operation we have done at different services. We can revert the transaction
either via events are API calls based on our need. This is called SAGA. It will
have a binary state. Either Success or failure. Success, all transaction has
been completed on a different distributed system. Failure, all transaction
whatever done had been reverted successfully on a different distributed system.
IT will increase application reliability. But it will increase application
complexity. Based on our business we need to check whether it will be
applicable or not. In some cases, it doesn't require to revert the entire
transaction in case of failure in one entity. We can find some other ways like
fall back mechanism on the backend or notify the end-user to do some action
against it. But it will purely be based on the business.
CQRS:
All services are working fine. When more customers will use
the application I can scale my services. How about MY DB. We need to scale it
vertically or we can add one more replica of my DB. so the read and write
operation will be handled by separate DBS. In my scenarios, I have added Redis
for my read operation, which will be called very frequently. So all my requests
will be handled by Redis itself. it doesn't require the DB call. It's up to you
can decide which kind of DB either SQL or NoSQL based on the performance and
business. But deciding on multiple DBS should depend on the load on the
database.
STRANGLER:
Services are working fine based on the customer load. I
have migrated my application from monolithic to microservices. Either I can do
complete replace or I can roll out a set of APIs. I have decided to move a set
of API that will be used by a set of customers instead of a complete
replacement. Even if there will be a problem set of customers will get affected
for that particular feature alone. Still, my services and application will run
without any issues. I can migrate API to microservices in incremental order.
This is called the Strangler pattern.
Retry
or Circuit Breaker:
I have added retry and circuit breaker in all the patterns
based on the need. It's kind of addons from my point of view. It will increase
application reliability.
Conclusion:
I have designed these patterns based on my need. If you
have any suggestions or improvements on this please let me know. Comments are
always welcome.

Comments
Post a Comment