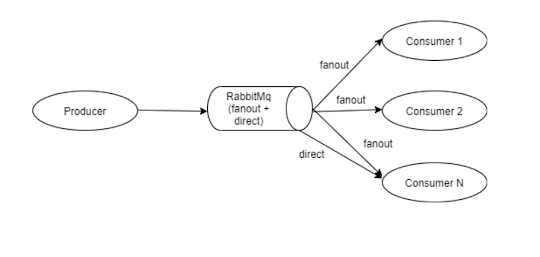
RabbitMQ Retry Architechure

Event-Driven architecture services communicate by messages using Message brokers like RabbitMQ. The entire transaction will be completed if the message will get processed successfully. While processing messages from Queue there will be a chance of failure due to invalid data or resources unavailable. If data is invalid, then the message will get failed while processing. In this case, we can reject the message from the Queue and needs to send a notification to the corresponding services about the invalid data. Resource unavailability will be based on completing the entire transaction in the distributed system. The availability time will vary from milliseconds to seconds in distributed systems. Once Resource is available, we need to process the message again. We need to retry the message in case of failure that will increase our system reliability and accuracy. Retry Mechanism: We can retry the message from RabbitMQ using two approaches. 1) Rollback ...